Encoding transforms data into another format using a scheme that is publicly available so that it can easily be reversed. It does not require a key as the only thing required to decode it is the algorithm that was used to encode it.
Usually encodeing is done to convert data from one form to another to make it compatible with a specific system. ASCII, UTF-8, UTF-16, UTF-32, ISO-8859-1, and Windows-1252 are valid encoding methods for the English language. Note that UTF-8, UTF-16, and UTF-32 are Unicode encodings, and they can represent characters from other languages, such as Arabic and Japanese.
ASCII#
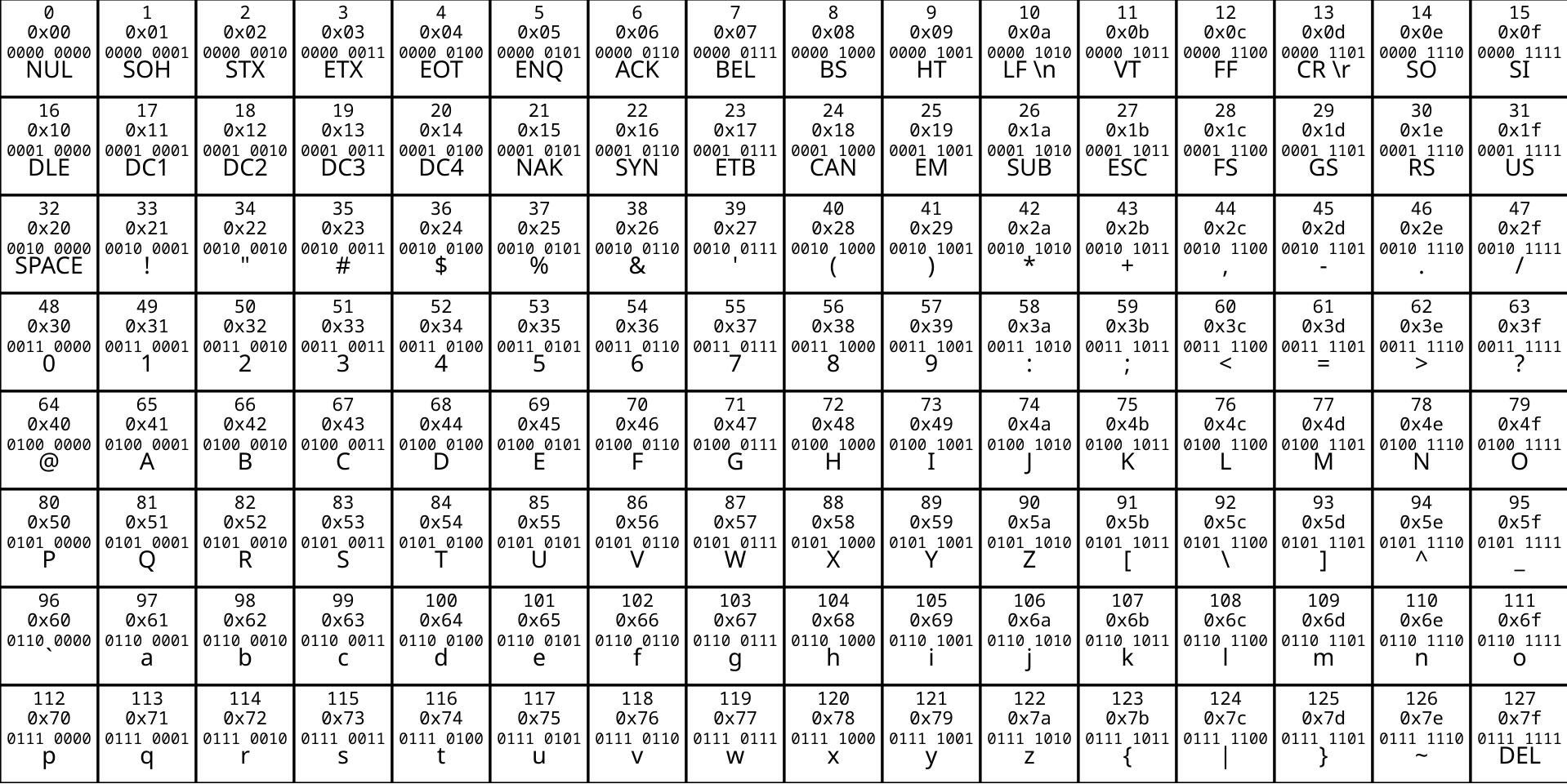
ASCII stands for American Standard Code for Information Interchange, and it is an early character encoding from 1963 that uses numbers 0-127 to represent English letters, digits, punctuation, and some control characters.
- Total Characters: 128 (numbered (0) to (127)).
- Control Characters (0-31, 127): Non-printing formatting and device controls (e.g., Line Feed, Backspace, Escape).
- Printable Characters (32-126): Letters, numbers, spaces, and punctuation (e.g., Space = 32, ‘A’ = 65, ‘a’ = 97).
- Modern Evolution: ASCII forms the base of modern encoding systems. The first 128 characters of Unicode and UTF-8 are exactly identical to ASCII.
A complete, comprehensive list of all 128 codes is available on the Linux Man Pages ↗ reference. Also refer https://www.ascii-code.com/ ↗
ASCII provided a way to encode the English alphabet; however, we need an encoding to support other European languages such as Spanish (ñ, ¿), German (ß, ü), Polish (ł, ń), Czech (č, ř), and Romanian (ș, ț), to name a few. ASCII uses 7 bits, and with an eighth bit, we get 128 more characters to cover. However, the reality is more challenging; the additional 128 characters are not enough to cover all the letters of the European languages. The ISO/IEC 8859 Series (International Standards) created several standards; each standard covered a set of languages:
- ISO-8859-1 (Latin-1): Covered Western European languages like German (ß, ü), French (é, ç), Spanish (ñ, ¿), Italian, Portuguese, Catalan, and Nordic languages (e.g., Icelandic ð/Ð). Check this link(opens in new tab) ↗.
- ISO-8859-2 (Latin-2): Supported Central/Eastern European languages like Polish (ł, ń), Czech (č, ř), Hungarian (ő, ű), Croatian (đ), Romanian (ș, ț), and Slovak. Check this link(opens in new tab) ↗.
In other words, if your document is saved using ISO-8859-1 and later read and displayed as if it were saved using ISO-8859-2, non-English letters are likely to be displayed differently.
Unicode#
Unicode is a universal character encoding standard maintained by the Unicode Consortium. It assigns unique code points to characters from all modern and historical writing systems worldwide. Unicode supports the interchange, processing, and display of text in diverse languages.
- https://home.unicode.org/ ↗
Unicode is a character set standard that assigns a unique number to every character across all languages. Examples: - U+0041 = Latin “A”
- U+03A9 = Greek “Ω”
- U+3042 = Japanese Hiragana “あ”
- U+1F602 = The laughing emoji (😂)
Unicode 17.0 is currently the latest version of the Unicode Standard. It defines close to 157 thousand characters, almost 4,000 of them are emoji sequences.
The Unicode Standard defines a codespace: a sequence of integers called code points in the range from 0 to 1114111, notated according to the standard as U+0000–U+10FFFF. The codespace is a systematic, architecture-independent representation of The Unicode Standard; actual text is processed as binary data via one of several Unicode encodings, such as UTF-8. In this normative notation, the two-character prefix U+ always precedes a written code point, and the code points themselves are written as hexadecimal numbers. At least four hexadecimal digits are always written, with leading zeros prepended as needed. There are a total of 1112064 valid code points within the codespace.
UTF-8, UTF-16, and UTF-32#
While Unicode provides the universal directory of characters and their numbers, computers still need instructions on how to save these numbers in binary (1s and 0s). That is where UTF encodings come in. UTF stands for Unicode Transformation Format.
- UTF-8:
- The world’s dominant text encoding. It is highly efficient, uses 1 to 4 bytes per character/Unicode point dynamically, and is backward-compatible with standard ASCII.
- ASCII characters (
U+0000toU+007F) use exactly 1 byte, identical to the original ASCII, ensuring seamless backward compatibility. - Non-ASCII characters like Ω (
U+03A9) use 2 bytes, while complex scripts or emoji like 🔥 (U+1F525) require 4 bytes. This flexibility allows us to cover the Unicode standard without wasting bytes.Because of its efficiency, nearly every modern webpage is transmitted using UTF-8.
- UTF-16:
- Encodes characters in either 2 or 4 bytes. It provides more predictable text lengths but can result in larger file sizes for standard Western alphabets.
- Common characters, like most Latin, Cyrillic, or Chinese Hanzi, fit in 2 bytes; however, rarer ones, like emoji or ancient scripts, require a pair, i.e., two 16-bit units totaling 4 bytes.
- For example, the letter
Ais encoded asU+0041, while the emoji 🔥 needs two and is encoded asU+D83D U+DD25.
- UTF-32:
- Uses exactly 4 bytes for every single character. It allows for very fast internal memory access but wastes a significant amount of space
- For example,
Ais encoded asU+00000041and 🔥 is encoded asU+0001F525.
Base Encoding#
Base encoding refers to translating arbitrary data (binary or text) into a safe, printable sequence of text characters. The most popular format is Base64, which translates raw data into 64 standard ASCII characters (A-Z, a-z, 0-9, +, and /) to ensure safe transmission across text-only networks.
Common Base Encoding Types
- Base64: The industry standard. Converts every 3 bytes of data into 4 characters. Used for emails (SMTP), web transfers (HTTP), and embedding images/files into HTML or JSON.
- Base32: Uses a 32-character set (A-Z and 2-7). It is slightly less compact than Base64 but case-insensitive and easier for humans to read or type.
- Base16 (Hexadecimal): Uses 16 characters (0-9 and A-F). It represents every byte as two characters, making it highly readable but twice as large as the original data.
- Base58: Used heavily in cryptocurrencies (like Bitcoin). It removes visually ambiguous characters like “0” (zero), “O” (capital o), “I” (capital i), and “l” (lowercase L) to prevent typos.
This is commonly used when sending or saving data is base encoding, which is not for any specific language.
Encode a file:
base64 path/to/file
Decode a file:
base64 [-d|--decode] path/to/fileBase64#
Step 1: Take ASCII value of cahracters and convert to binary and merge to form group of 24bits.
Step 2: Divide this into groups of 6bits and Convert to Decimal
Step 3: Convert to corresponding characters of the decimal values from the previous step from the below table
| Index | Character | - | Index | Character | - | Index | Character |
|---|---|---|---|---|---|---|---|
| 0 | A | 26 | a | 52 | 0 | ||
| 1 | B | 27 | b | 53 | 1 | ||
| 2 | C | 28 | c | 54 | 2 | ||
| 3 | D | 29 | d | 55 | 3 | ||
| 4 | E | 30 | e | 56 | 4 | ||
| 5 | F | 31 | f | 57 | 5 | ||
| 6 | G | 32 | g | 58 | 6 | ||
| 7 | H | 33 | h | 59 | 7 | ||
| 8 | I | 34 | i | 60 | 8 | ||
| 9 | J | 35 | j | 61 | 9 | ||
| 10 | K | 36 | k | 62 | + | ||
| 11 | L | 37 | l | 63 | / | ||
| 12 | M | 38 | m | ||||
| 13 | N | 39 | n | ||||
| 14 | O | 40 | o | ||||
| 15 | P | 41 | p | ||||
| 16 | Q | 42 | q | ||||
| 17 | R | 43 | r | ||||
| 18 | S | 44 | s | ||||
| 19 | T | 45 | t | ||||
| 20 | U | 46 | u | ||||
| 21 | V | 47 | v | ||||
| 22 | W | 48 | w | ||||
| 23 | X | 49 | x | ||||
| 24 | Y | 50 | y | ||||
| 25 | Z | 51 | z |